Recent video question answering benchmarks indicate that state-of-the-art models struggle to answer compositional questions. However, it remains unclear which types of compositional reasoning cause models to mispredict. Furthermore, it is difficult to discern whether models arrive at answers using compositional reasoning or by leveraging data biases. In this paper, we develop a question decomposition engine that programmatically deconstructs a compositional question into a directed acyclic graph of sub-questions. The graph is designed such that each parent question is a composition of its children. We present AGQA-Decomp, a benchmark containing 2.3M question graphs, with an average of 11.49 sub-questions per graph, and 4.55M total new sub-questions. Using question graphs, we evaluate three state-of-the-art models with a suite of novel compositional consistency metrics. We find that models either cannot reason correctly through most compositions or are reliant on incorrect reasoning to reach answers, frequently contradicting themselves or achieving high accuracies when failing at intermediate reasoning steps.
Measuring Compositional Consistency for Video Question Answering

@inproceedings{Gandhi2022Measuring,
title={Measuring Compositional Consistency for Video Question Answering},
author={Mona Gandhi*, Mustafa Omer Gul*, Eva Prakash, Madeleine Grunde-McLaughlin, Ranjay Krishna, Maneesh Agrawala},
booktitle ={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
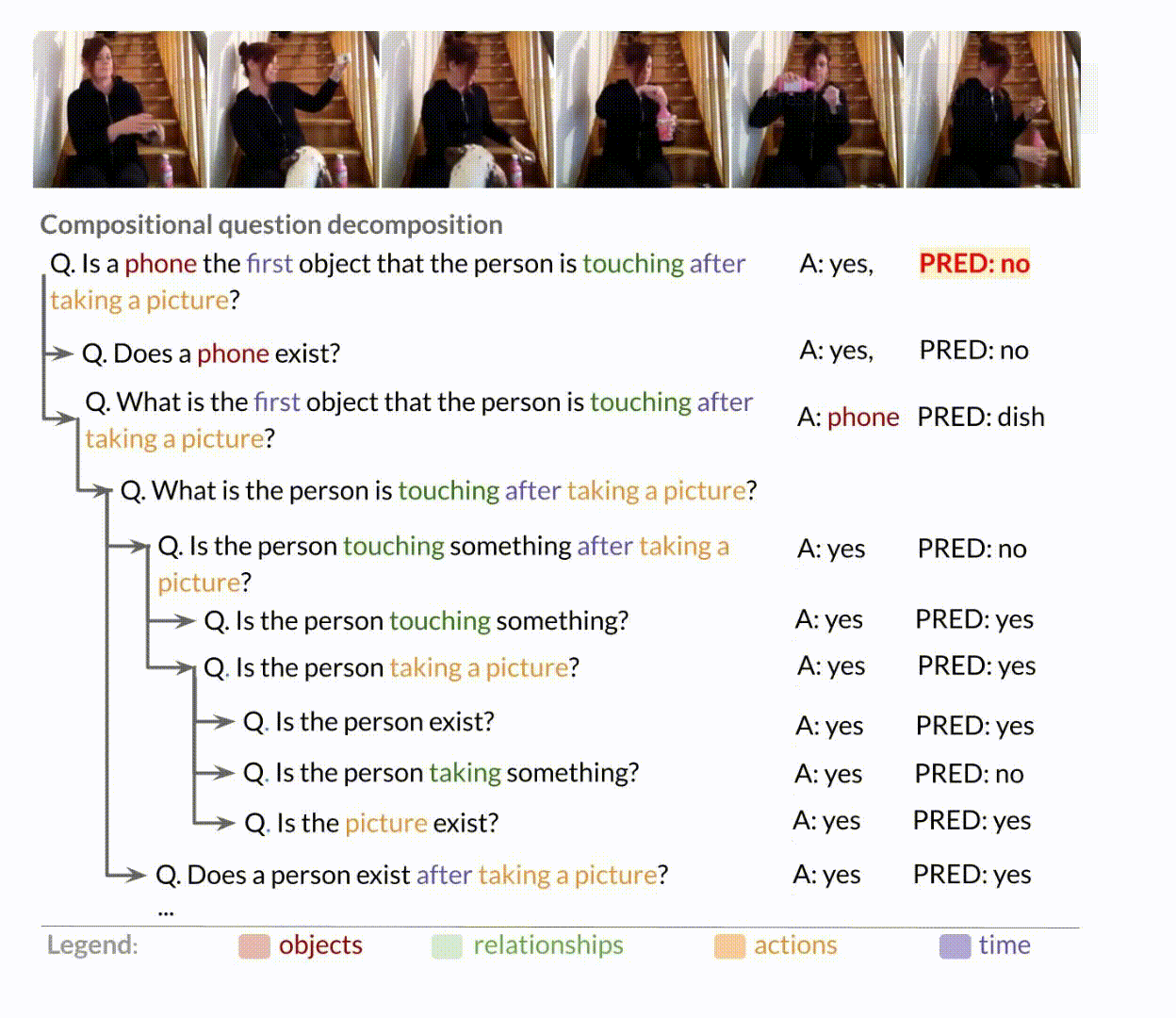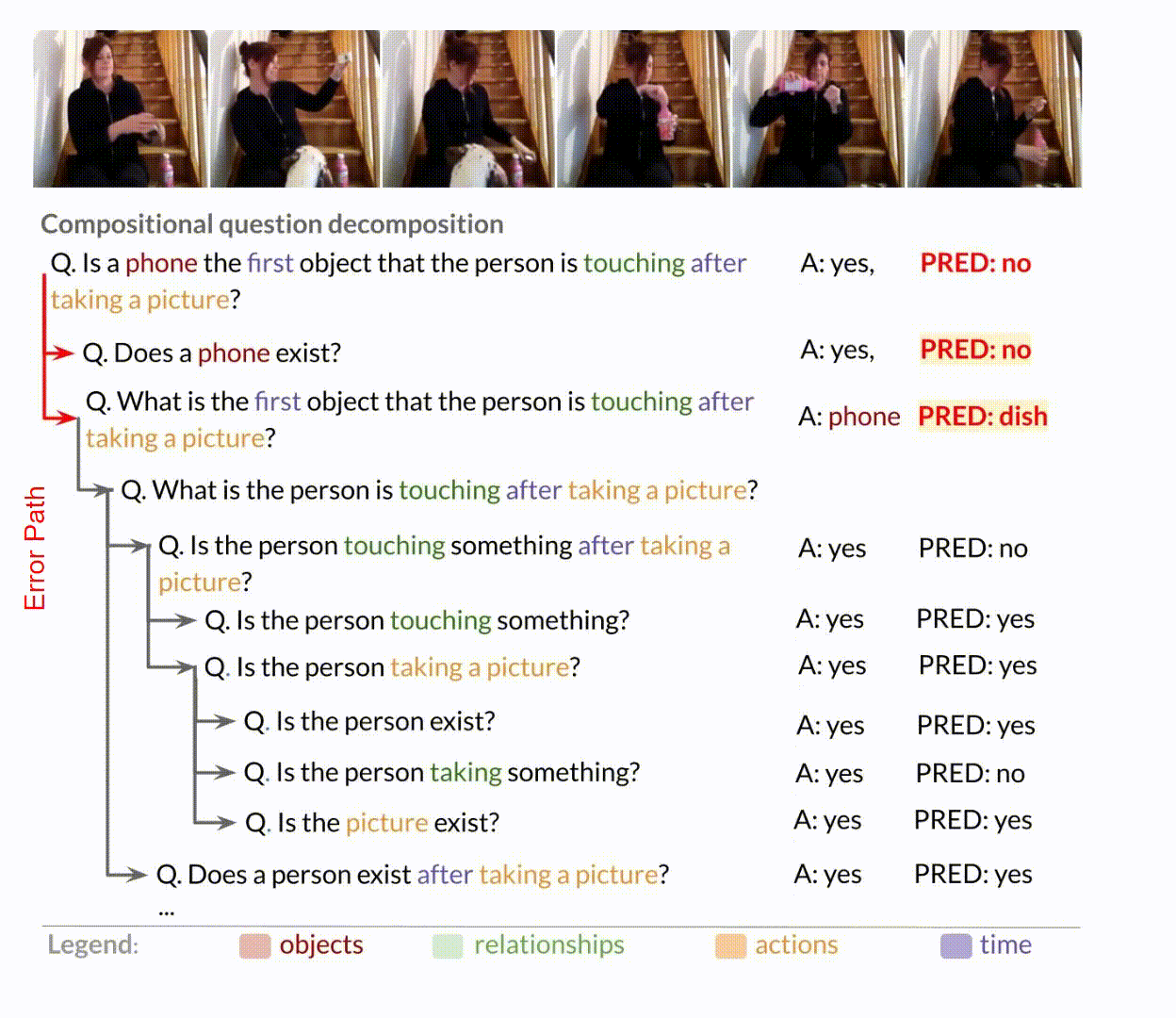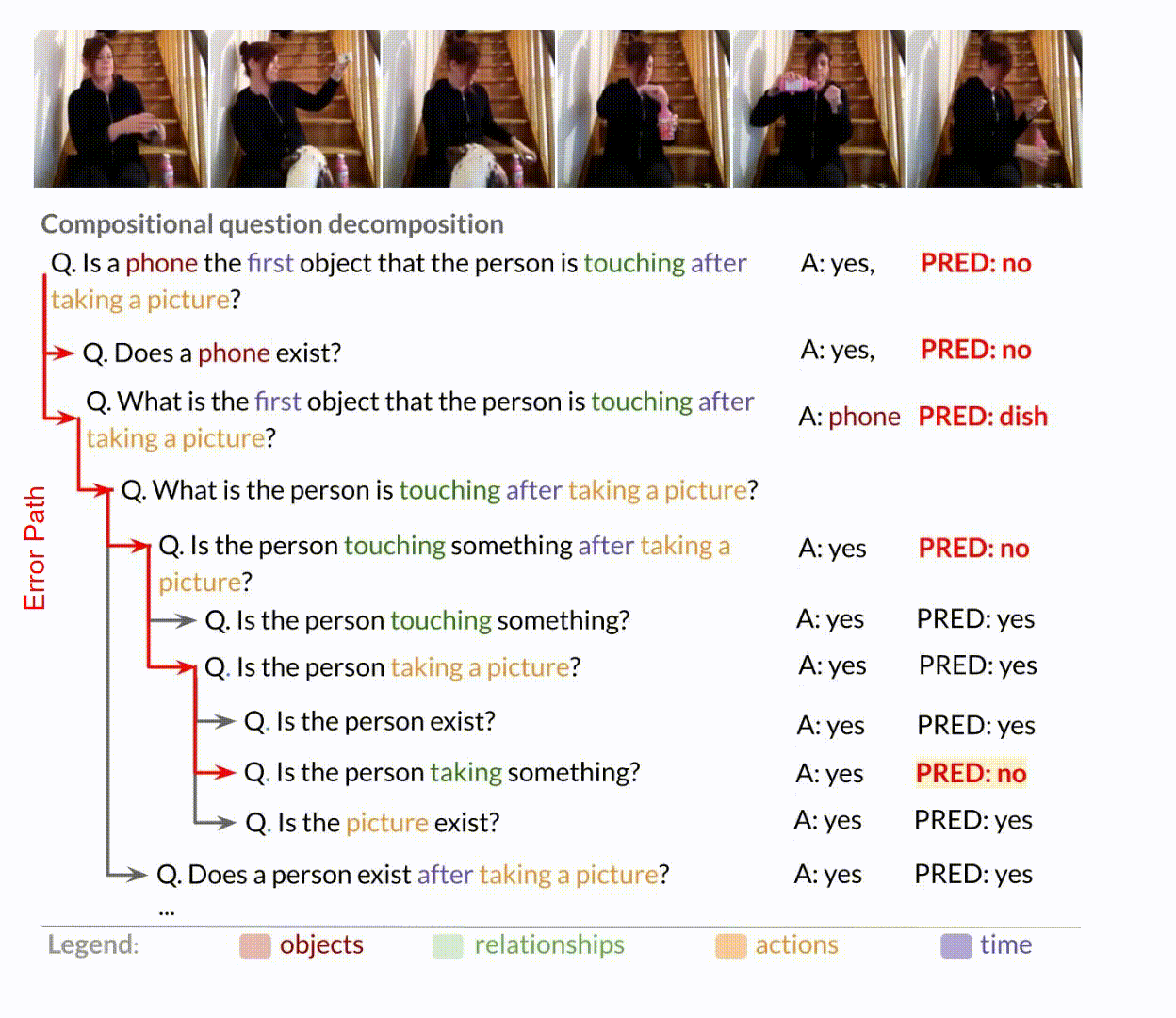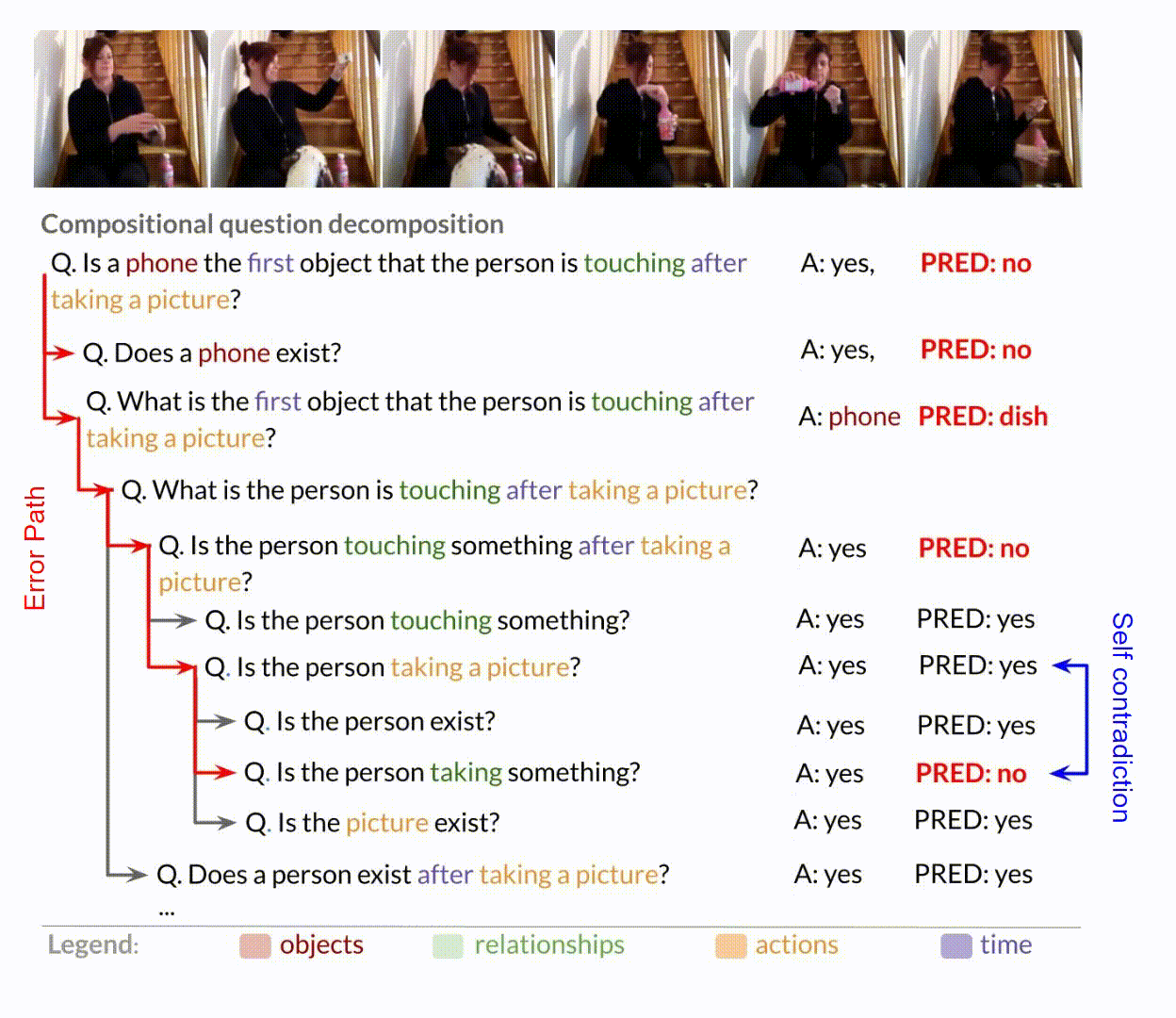
}Decomposing AGQA Questions
Question: What is the person in front of first after eating some food? Program: first(objects_after(objExists(person), relationExists(in front of), interactionExists(objExists(person), relationExists(eating), objExists(food))))


Recursive iteration over the functional program to form the DAG
Directed Acyclic Graph (DAG)
Metrics
The sub-questions enable us to identify difficult sub-questions and study which compositions cause models to struggle. It also allows us to test whether models are right for the right reasons. To measure models' performance, we design the following novel metrics:
Compositional accuracy
If the model answers all children questions correctly, does it answer the parent question correctly?

 a question that is answered correctly
a question that is answered correctly
 a question that is answered incorrectly
a question that is answered incorrectly
Right for the wrong reasons
If the model answers a child question incorrectly, does it still answer the parent question correctly?

a question that is answered correctly
a question that is answered incorrectly
Internal Consistency
Do the model's answers reflect a consistent understanding of visual events?
 parent and child answers are consistent
parent and child answers are consistent
 parent and child answers are inconsistent
parent and child answers are inconsistent
Results
On evaluating three state-of-the-art video question answering models, HCRN, HME and PSAC using our DAGs and metrics, we get the following results:
- For a majority of compositional reasoning steps, models either fail to successfully complete the step or rely on faulty reasoning mechanisms.
- They frequently contradict themselves and achieve high accuracies even when failing at intermediate steps.
- Models struggle when asked to choose between or compare two options, such as objects or relationships.
- There is a weak negative correlation between internal consistency and accuracy across DAGs, suggesting that the models are frequently inaccurate and propagates this inaccuracy due to its internal consistency.
We believe that our decomposed question DAGs could further enable a host of future research directions: from promoting transparency through developing interactive model analysis tools.
AGQA-Decomp Data
Contains hierarchies with answers for balanced train and test versions of AGQA 2.0
Contains hierarchies with answers for unbalanced train and test versions of AGQA 2.0
Contains CSV files that should be used to train and test models
Steps to recreate results



